
Today at Tidelift’s annual Upstream event, I’m giving a talk entitled Software + People: An optimistic (and practical) way forward for the open source software supply chain. Over the last few months, I’ve observed that there is an important element missing from much of the dialog about how we solve today’s open source software supply chain challenges.
People.
Here’s my hypothesis:
- Software tools alone are an incomplete solution to open source supply chain challenges.
- Software tools alone can’t meet emerging open source supply chain security requirements.
- Therefore, a better approach to improving the health and security of the open source supply chain would bring together software AND people.
Let me break this down a bit more.
Software tools alone are an incomplete solution to open source supply chain challenges
 For several decades now, software-only tools have been the most popular way to assess open source risk. I went to the Wayback Machine and captured this image of Black Duck, a pioneering open source risk management tool, from March, 2004. Fast forward to today, and there is an entire category called Software Composition Analysis with established companies making hundreds of millions of dollars in revenues. It even has its own Gartner Magic Quadrant!
For several decades now, software-only tools have been the most popular way to assess open source risk. I went to the Wayback Machine and captured this image of Black Duck, a pioneering open source risk management tool, from March, 2004. Fast forward to today, and there is an entire category called Software Composition Analysis with established companies making hundreds of millions of dollars in revenues. It even has its own Gartner Magic Quadrant!
With as much money as has been spent on scanning tools over the years, you would think that open source health and security would be a solved problem by now.
It’s not. As Log4Shell and a steady cadence of lesser-known software supply chain challenges have continued to percolate over the past few years, many technology leaders have had more than their share of table flip, pull your hair out moments.
So why is the software-only approach to managing open source health and security incomplete?
First off, one limitation of software-only approaches is that they are inherently backward looking. They can tell you many things about the past, including mapping known vulnerabilities from the National Vulnerability Database for an open source project. But they can’t tell you much about the future. What are the release engineering practices for the project? How does the project handle incident response? Does it have a responsible disclosure policy in place, and if so, what is it? In other words, software-only approaches are reactive, not proactive.
Another issue with software-only approaches to open source management relates to the fidelity of metadata. Most software-only tools are essentially “scraping” information from the internet, which can create a garbage-in, garbage-out problem. Without humans actually verifying the information is correct and properly contextualized, you often end up with false positives—and false negatives. Over the past few years, I can’t tell you how many times I’ve heard from application development leaders how frustrated they are with the noise they get from scanner reports. It is sometimes hard to separate what is an actual issue from what is a false positive, or to understand whether a particular issue is actually meaningful in their use case.
Developers are frustrated because they end up wasting time poring through scanner reports, researching issues that aren’t actually issues at all, or going back and forth with security teams trying to make the case for why it is OK to wave off a scanner-thrown flag. In many cases it’s also frustrating and stressful for the open source maintainers who watch over the project, when they get the same false alarms blindly reported to them over and over again.
Here’s the kicker. Say there is a legitimate issue that is uncovered by a scanning tool… now you have to figure out how to remediate it. Your team didn’t write the code, so you’re probably not in a great position to investigate or fix it yourself. You almost certainly don’t have write privileges to the project itself so at best you can hope the maintainer of the code comes up with a fix or you have to try to work around it or replace the offending code.
This is the third key shortcoming of scanning tools—they give you diagnosis without a proper treatment plan.
Software tools alone can’t meet emerging open source software supply chain requirements
 One of the important silver linings to emerge from the recent wave of software supply chain attacks is increased attention from both governments and organizations on improving software security standards. The May 2021 White House Executive Order on Cybersecurity launched a whole set of efforts within the U.S. government to improve practices around security and software provenance.
One of the important silver linings to emerge from the recent wave of software supply chain attacks is increased attention from both governments and organizations on improving software security standards. The May 2021 White House Executive Order on Cybersecurity launched a whole set of efforts within the U.S. government to improve practices around security and software provenance.
One such effort was spearheaded by the NTIA, which was tasked with defining the minimum requirements for a software bill of materials (SBOM). (If you aren’t familiar with the term SBOM, you can think of it as a list of the ingredients that make up a piece of software.)
For proprietary software products, the SBOM should be relatively straightforward to produce, as the supplier that created the product and wrote the code should be able to provide all of the requested answers. But in the open source world, things get a little trickier.
Here, for example, is the list of the minimum elements the NTIA is proposing be included in an SBOM. As you read through this list, for open source software, think about whose job it is to provide this data. Some of the details can be sucked up by scanning tools. But for many of these data points, the maintainer in charge of the open source project is really the only person who can provide this information authoritatively. I’ve marked the items that can be answered by software alone with a ✅ and the ones that likely need help from a maintainer with a ⛔. You might quibble with my scoring, but the fact of the matter is that open source project maintainers are a better authoritative source for most of this SBOM information than downstream software tools.
⛔ Supplier name
✅ Component name
✅ Version of the component
⛔ Other unique identifiers
⛔ Dependency relationship
✅ Author of SBOM data
✅ Timestamp
⛔ Hash of the component
⛔ Lifecycle phase
⛔ Other component relationships
⛔ License information
⛔ Link to vulnerability data sources
 Another emerging set of U.S. government requirements to reduce cybersecurity supply chain risk are coming out of NIST. In the recently updated NIST Special Publication NIST SP 800-161r1 Cybersecurity Supply Chain Risk Management Practices for Systems and Organizations, three key principles are listed that all need help from maintainers to produce:.
Another emerging set of U.S. government requirements to reduce cybersecurity supply chain risk are coming out of NIST. In the recently updated NIST Special Publication NIST SP 800-161r1 Cybersecurity Supply Chain Risk Management Practices for Systems and Organizations, three key principles are listed that all need help from maintainers to produce:.
⛔ If an enterprise uses an open source project that does not have an SBOM, 1) contribute SBOM generation to the open source project, 2) contribute resources to the project to add SBOM, or 3) generate an SBOM on first consumption
⛔ Understand and review the open source community’s typical procedures regarding provenance, configuration management, sources, binaries, reusable frameworks, reusable libraries’ availability for testing and use, and any other information that may impact levels of exposure to cybersecurity risks
⛔ Evaluate and periodically audit the OSS’s supply chain as provided by the open source developer
The work for maintainers is starting to pile up, but the load gets even heavier when you look at the requirements from the awesome new security scorecards being developed as a part of the OpenSSF Security Scorecards project, where practically every proposed “check” requires a maintainer to be involved in order to authoritatively satisfy it (and in many cases, to even accurately measure it!):
⛔ Binary-Artifacts
⛔ Branch-Protection
⛔ CI-Tests
⛔ CII-Best-Practices
⛔ Code-Review
⛔ Contributors
⛔ Dangerous-Workflow
⛔ Dependency-Update-Tool
⛔ Fuzzing
⛔ License
⛔ Maintained
⛔ Pinned-Dependencies
⛔ Packaging
⛔ SAST
⛔ Security-Policy
⛔ Signed-Releases
⛔ Token-Permissions
⛔ Vulnerabilities
⛔ Webhooks
Another example: a quick review of the recent OpenSSF Open Source Software Security Mobilization Plan shows that it would also need participation from upstream open source maintainers to accomplish virtually all of the ten recommended streams of investment in upstream projects:.
⛔ 1. Baseline Secure Software Development Education
⛔ 2. Risk Assessment Dashboard for OSS
⛔ 3. Digital Signatures to Deliver Enhanced Trust
⛔ 4. Replacement of Non-Memory-Safe Languages
⛔ 5. Open Source Security Incident Response Team
⛔ 6. Accelerate Discover and Remediation of New Vulns
⛔ 7. Third Party Audits/Code Reviews and Remediation
⛔ 8. Data Sharing to Determine Critical Projects
⛔ 9. SBOMs Everywhere: Security Use Cases, Tooling
⛔ 10: Build Systems, Package Managers, and Distribution Systems
In sum, lots of useful ideas are being floated about the requirements for keeping our open source software supply chain healthy and secure.
Now we need to start thinking more about who is actually going to do all of the work, and why.
A better approach to reinforcing the open source supply chain: software + people
Looking at those lists of new requirements above, one thing becomes abundantly clear. The amount of information that can be collected via software tools alone ✅ is vastly less than the information that will need human help to document ⛔. In most cases, those humans we’ll need to call on are the independent open source maintainers who created the software in the first place and toil away keeping it up to date, often on a volunteer basis.
There’s one big problem: maintainers are already overworked, underpaid, and under-appreciated, and now we are asking them to do even more.
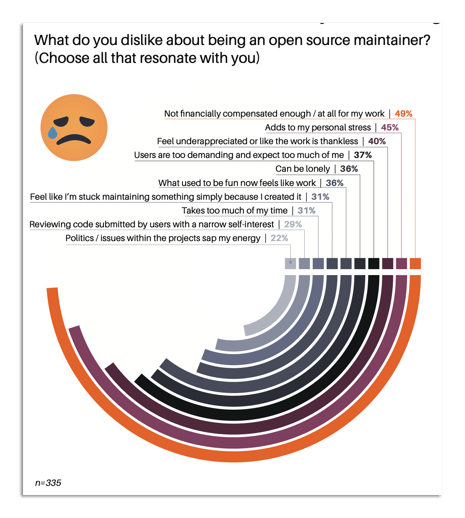
In our 2021 Tidelift open source maintainer survey, we asked maintainers to tell us what they disliked about being a maintainer. What they shared is that they don’t like 1) not being financially compensated enough (or at all) for their work; 2) maintenance work adding to their personal stress; 3) being under-appreciated and doing thankless work; and 4) dealing with users who are too demanding and expect too much of them.
With that context in mind, how can we reasonably expect to ask them to do even more?
Therein lies the problem. We need to improve the health and security of the open source software all of our organizations rely on and our current solutions aren’t getting the job done on their own. We also can’t expect overburdened maintainers to take on new a whole load of new responsibilities without our support.
A new compact between organizations and maintainers
I suggest we create a new compact between organizations and open source maintainers that leads to a mutual win-win.
As organizations, what we shouldn’t do is:
- Inundate maintainers with complaints, false positives, and noise that add to their stress and takes the joy out of their work.
What we should do is:
- Pay the maintainers to create the capacity for them to address these important challenges and get compensated well for their efforts.
- Find additional ways to support their work through process support, load sharing, and other innovations that reduce their burden, toil, and stress.
- Thank them and treat them as the heroes they are!
In return, we’ll contribute to a more healthy, happy, and well-cared for community of open source maintainers, who will be better supported and provided with more resources to do the work that organizations need done to keep open source safe and secure.
We’ve come a long way since the early days of software-only open source diagnostic tools, and we’ve learned a lot along the way. I’m optimistic that we can make open source work better—for everyone—as long as we keep our focus on the actual humans who write and maintain the code our digital society depends on.

 50 Milk St, 16th Floor, Boston, MA 02109
50 Milk St, 16th Floor, Boston, MA 02109