
As I’ve written about before, the packaging of open source software is trending towards increasingly granular modules, distributed through a collection of (generally) language-specific package managers. The largest of these is npm, carrying over 648,000 packages.
When writing about the complexities of managing modular software, I cited one particular challenge: the need to understand and navigate a complex dependency tree, with hundreds or thousands of dependencies potentially getting pulled into your build.
As a developer, it’s almost impossible to know everything about each of these dependencies, and as a recent viral blog post by David Gilbertson demonstrated, a malicious actor could— relatively easily—slip unwanted and intrusive code into your application through one of these many agents that you’ve introduced into your dependency tree.
Let’s take an objective look at the dependencies of the most-used open source packages.
The distribution of dependencies
The specific mechanisms for tracking dependencies vary across open source communities, making it challenging to compare across languages or package managers. Because of this, we limited this study to a collection of fourteen package managers for which we have reliable dependency data (spanning over 6.9 million distinct versions of open source packages).
As demonstrated in the graphic below, the typical number of dependencies for a representative open source package varies widely between ecosystems. For example, npm clearly has the largest spread of dependency counts, but other large communities—specifically, Rubygems and Pypi—have much tighter distributions. This indicates that the number of dependencies a package pulls in is less related to the size of the ecosystem, and more to the customs and norms of the community itself.
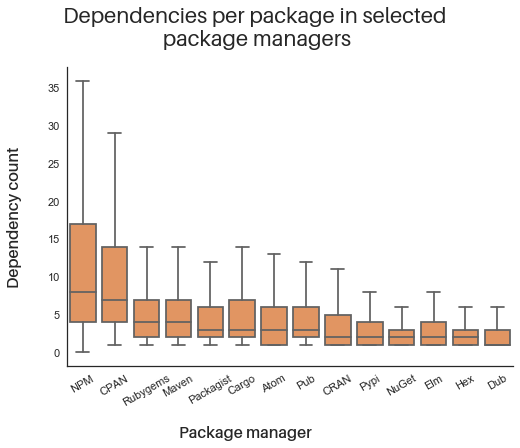
While the spread varies significantly across package manager ecosystems, the average number of dependencies for a package—the horizontal line bisecting each orange box in our visualization—is actually fairly consistent across communities. With the exception of npm and CPAN, packages in most ecosystems average fewer than five dependencies.
I should also note that I excluded all outliers from this graphic for the purpose of legibility. Had they been included, the mean dependency count would increase, with a much broader range of dependencies.
What does this mean for your software?
In the modern era of software development, developers incorporate many distinct open source packages into their applications to help speed up development time and improve software quality. The actual counts can vary across developers and ecosystems—for example, a Python developer might be less likely to pull in dozens of additional packages than a JavaScript developer would, for example.
But regardless of the programming language, each new package pulls in a network of additional (so called transitive) dependencies of its own. As we illustrate above, the average package in most ecosystems pulls in an additional five dependencies, adding to the overall software complexity.
Why is this important?
Software today is like an iceberg: you may actively pull in just a few dependencies yourself, but those known dependencies are only a small percentage of your actual dependency tree. The additional dependencies brought in by packages that your application relies on are equally important to the security, licensing, and future performance of your software.
We’ve written before about steps that we can all take towards improving the sustainability of open source software, but maintaining all of your dependencies—not just the ones you directly bring in—is key to ensuring the health of your application.
The open source that we all rely on extends far beyond the first layer of packages in our applications. We should seek to understand and ensure the health of every package we use, whether hidden in our transitive dependencies or not.
If you are interested in learning more about your software dependencies, consider signing up for updates or following us on Twitter.

 50 Milk St, 16th Floor, Boston, MA 02109
50 Milk St, 16th Floor, Boston, MA 02109