
Open source changes at a breathtaking rate in modern software development. Development teams make many choices each day about what packages to start or stop using. Impacting these choices are thousands of dependency graphs, where package maintainers are also making choices continuously. New versions ship, security weaknesses emerge, packages are abandoned, and contributors change.
We are living in an era where reacting to late-stage risk alone is no longer enough to secure your organization's software. There are too many vulnerabilities to respond to. Open source software supply chain threats are much broader than what CVEs tell us. And managing all of this at scale is overwhelming.
Getting the data you need to proactively tackle open source supply chain threats
Accurate, continuously updated information is key to empowering your teams. The path out of late development stage fire drills is using data to drive action, earlier. Without this data, the scale of independent decision making is costing your business time and money. Inaccurate or incomplete information is also costing your business time and money, and giving you a false sense of security.
Today, we are announcing new ways to access and use unique, human-validated data we’re curating with our maintainer partners. This data is now available to our customers via API for seamless integration into existing workflows and business intelligence tools. Our earliest customers have used this in their internal development platforms, or as a complement to SCA output.
We’re also announcing a new and easy way for our customers to attest to the secure software development practices used in their open source software supply chain. If you will need to comply with U.S. government cybersecurity guidelines—we’ve got you covered for your open source. Read the docs on packages, releases, and vulnerability recommendations direct from maintainers, or read on to find out how our data saves teams time and effort.
Data collected at the source
There are tools in the market today that provide machine-gathered data on open source security or development practices. Having access to a set of scraped metadata is useful for starting to build a picture of your open source usage.
Key questions to ask yourself:
- Are these tools supporting every ecosystem in your organization?
- How often is the data assessed for accuracy?
- What do you do when there is key information missing?
- Is passively consuming a set of data enough to drive real security outcomes?
Tidelift layers first-party intelligence and deeper human analysis on top of automated data gathering. This value can only be realized when we bring human capabilities to the problem. Tidelift and the maintainers we partner with do this tedious, but necessary, work on your behalf.
Your team is already spending their valuable time on this tedious work today. They are searching and assembling information. They are using their analytical skills to make big and small decisions. These decisions include navigating open source software they've long used, or new open source to begin using. They're trying to guess what the right metrics are to assess reliability over the long-term. This may be effective for a point in time decision, but it's not enough to manage the volume of change that must be continuously re-assessed.
Tidelift's approach is to enter into a business contract with maintainers. We pay them to uphold and attest to their own secure development practices. They review any vulnerabilities that show up in detail, providing key signals on false positives, workarounds, and how exploitable the risk is. This is intelligence directly from the creator, and drives more efficiency and better security for our customers.
We also have a dedicated team extracting data and intelligence on millions of open source packages. This data tells our customers if a project will be responsive to a reported security threat, if and when end of life may be scheduled, and what to do if a package or release is marked as deprecated. Imagine your teams having this at their fingertips in a fast, centralized way.
We unify the metadata, security, development practices, and future outlook data that we generate for every upstream package. You can find more details on the types of first-party maintainer-sourced data, Tidelift human-researched data, and automated data we provide via the Tidelift Subscription.
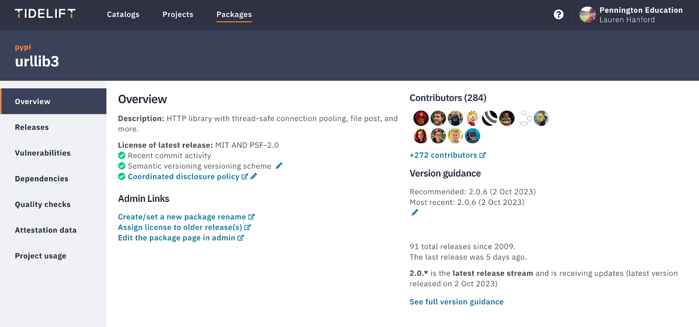
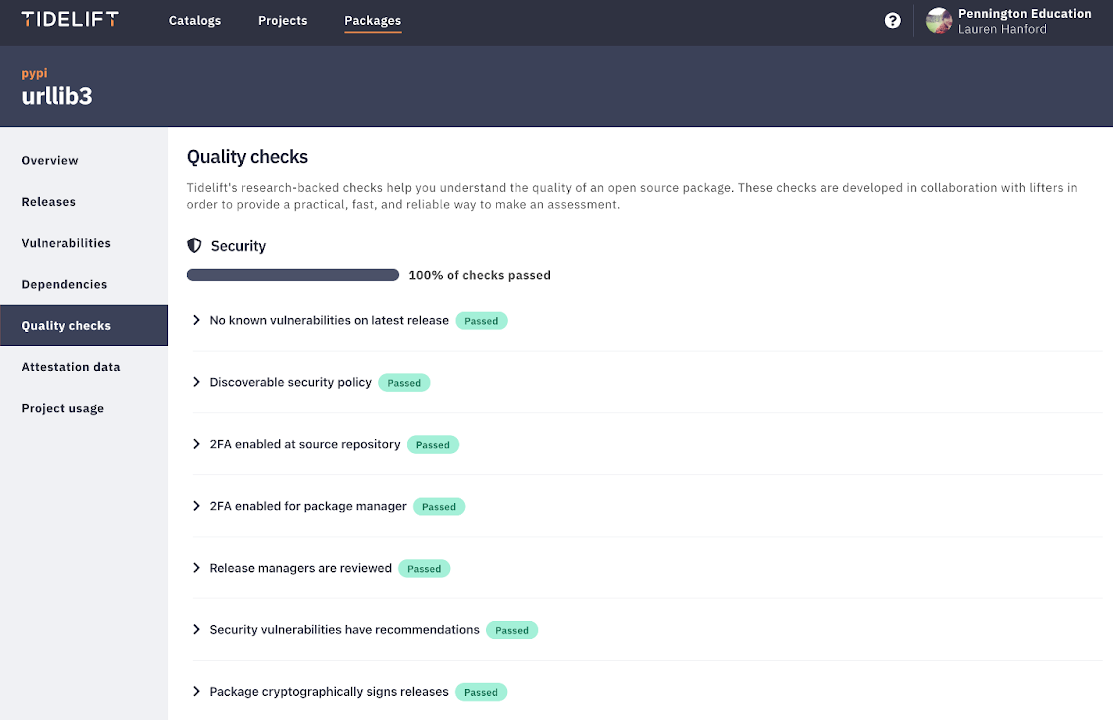
Here are two views in an example showing some of the secure software development practices data you can access via the Tidelift Subscription for urllib3, one of the most downloaded projects on PyPi used by nearly 1 million dependent repositories.
Helping organizations meet U.S. government cybersecurity compliance requirements
In September of 2021, the U.S. government announced a new requirement mandating that its software suppliers self-attest that they follow the secure software development practices outlined in the NIST SSDF. This also includes attesting to the secure development standards of the open source components used in their applications.
Ensuring compliance with the over thirty pages of NIST guidelines for internally developed software will be challenging in itself. As it relates to open source software, organizations need to ask: who is going to implement and document these secure development practices?
Tidelift’s unique model pays maintainers to implement and document the relevant secure development practices outlined in the NIST SSDF.
As part of the product capabilities we are announcing today, customers can confidently provide the self-attestation requirements proposed by the U.S. government. Our solution removes the effort needed to dynamically track compliance with the NIST SSDF practices for open source components going into their product. We automatically generate this attestation paperwork on a per-application or per-component basis—keeping it current, and stored for any later retrieval. You can check out the API documentation on this too.
Getting data from the source drives better outcomes
The results of leveraging this data within your organization are clear:
- Compliance, security, and development teams have the data they need to stop wasting cycles on point-in-time research
- Eliminates the organizational burden to refresh the assessment of packages each time an upstream release or dependency graph changes
- Security teams can present a more complete, proactive strategy on risk to the cybersecurity questions beginning to emerge in the boardroom
- Organizations selling software to the U.S. government have the secure development practices attestation reports needed to comply with mandatory government cybersecurity requirements
All of this can be achieved at scale, with minimal friction—Tidelift’s data APIs are built to layer in with the tool stack and processes you have in place today.
If your organization is not ready to take advantage of an API-based approach, we can still help! Learn more about how our core data can drive the same results through your organization using our turnkey management tools and workflows.
Tidelift is designed to be your organization’s proactive defense strategy for protecting your open source software supply chain. We’re able to deliver a centralized, structured, and continuously curated database of insights spanning millions of open source packages. We’re also investing in the upstream to capture attestations of secure development practices.
You can turn down the treadmill speed of responding to CVEs alone. Let us show you how! Learn more about these new capabilities in the Tidelift Subscription, or book a demo to dive in deeper.

 50 Milk St, 16th Floor, Boston, MA 02109
50 Milk St, 16th Floor, Boston, MA 02109