
Open source is everywhere—not just in startups or big companies but in practically every development team and every language imaginable.
And now we have a chance to better understand just how widespread it really is.
Earlier this week I wrote about Libraries.io, specifically about how its dependent repositories count provides us with the best understanding of the usage and interconnectedness of a given open source package. Today we want to look at which packages are the most interconnected within their given ecosystems, and we’ll do this through the lens of the dependent repositories count.
A comprehensive view of open source
One great aspect of Libraries.io is how expansively it attempts to cover all open source application level packages, rather than only the most popular or famous languages. Because of this, we can learn just as much about languages like JavaScript and Ruby as we can about Elixir, F#, or D.
With this breadth of coverage in mind, let’s take a look at the most interconnected packages in some of the more popular open source languages:
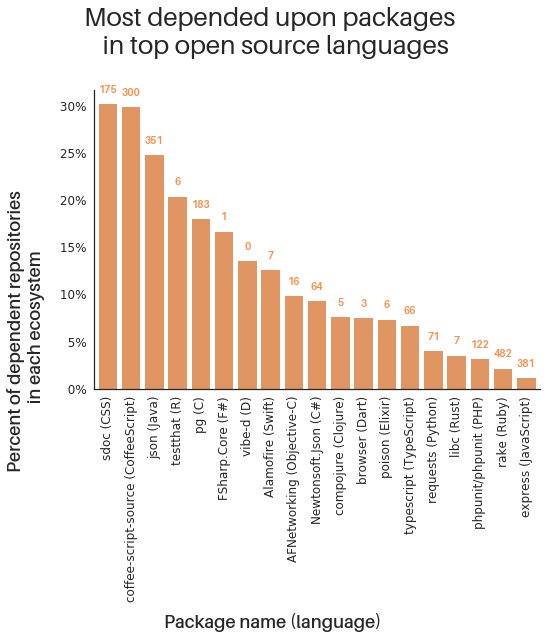
This figure shows which packages are the most relied upon relative to their own communities.
That said, it shouldn’t be read as an absolute ranking of the most important packages ever created, but more as a framing of which packages are the most heavily used within their own ecosystems, and how many of the total dependency interactions that individual package represents.
To break this graph down a bit, we took the package with the most repositories depending on it in each of the nineteen languages above (certain languages were omitted due to poor dependency tracking data) and divided the number of repos that depend on it by the total number of dependency connections within that language’s entire ecosystem.
The height of each bar represents the percentage of the total dependency connections within a language that are accounted for by that single package; the orange number floating atop each bar is the number (in the 1,000’s) of repositories that depend on that package.
What does this tell us about individual packages?
One of the most interesting trends we can spot in this data is around the use cases of many of these top packages. We see some JSON parsing libraries (json, poison, Newtonsoft.json), some unit testing packages (phpunit, testthat), and some HTTP libraries (requests, Alamofire).
The commonality shared by these packages is that they help solve relatively simple tasks that developers confront every single day. And this is one of the amazing aspects of open source: by sharing the work that we’ve created, we can eliminate hours and hours of menial or repetitive work, enabling developers to focus on making better products, tools, or discoveries.
But what does this mean for our community, aside from just confirming what we already knew about the effectiveness of open source at solving repetitive tasks and increasing modularity and flexibility?
Decentralization and modularity in open source
For starters, smaller and simpler packages should be a positive sign for newcomers: you don’t have to write an enormous and comprehensive library to become part of the community or for your work to be widely adopted. If anything, it’s better to write something simpler yet super-effective (although that’s easier said than done in most mature ecosystems).
The observed package modularity also means that the decentralized economics of open source are actually working. You may notice that some of the most popular languages in the world (JavaScript, Ruby, Python, etc.) are all towards the bottom of this list, meaning that the most depended upon packages represent a smaller percentage of all dependency connections in those communities.
This shows that the vibrancy and popularity of those languages begets a greater diversity of software development and more distinct packages, not consolidation into a core package. This, in turn, draws in more users and creates a network effect around those languages, furthering their popularity.
Why is this important? Because it means that as communities grow, they remain accessible to new projects, and these projects can still see mass adoption within the ecosystem. Openness to new work not only gives users and developers more autonomy regarding which software they choose to depend on, but it also allows for the communities to evolve in new directions. That is one reason why we’ve seen these ecosystems continue to broaden their scope, like Python becoming a leader in statistical analysis and data science.
So, to answer the question that began this article, what does make a top open source package? It’s clear that a package should effectively solve a repetitive and common task for developers, but that it must also do so for a community that supports modular packaging, as it’s within these communities that we see the greatest adoption of new software.
The combination of shared problem-solving and wide acceptance has helped make open source as awesome as it is. And this initial analysis represents our first step to forming a larger, data-driven understanding of the entire open source community—it’s so much more than the few most popular languages or projects. Given the breadth of the Libraries.io dataset, we have an opportunity to see even deeper into the health and vitality of our open source ecosystem.
If you are interested in learning more, consider signing up for updates or following us on Twitter.

 50 Milk St, 16th Floor, Boston, MA 02109
50 Milk St, 16th Floor, Boston, MA 02109