
Software composition analysis (SCA) tools have long been a popular way to identify security and licensing issues with open source packages. While helpful for identifying documented historical vulnerabilities in open source code, SCA tools also have developed a reputation for generating long and verbose reports with warnings about potential vulnerabilities, many of which ultimately end up being false positives. These reports are often handed over to development teams, who are asked to research and address hundreds of issues. This can be overwhelming and time-consuming.
False positives
SCA scan results will often provide a list of all of the vulnerabilities that have ever been reported for the dependencies you're using. But those vulnerabilities may not necessarily affect your application, based on:
- Whether it's used at build time or runtime
- Whether it's using all of the software's functionality, or just part of it
- Whether it's deployed in a user-facing environment
- Or many other factors
All of these factors can lead to a real vulnerability being a "false positive"—where you are being asked to fix something that doesn't actually affect you.
False positives end up becoming a drain on both developer and maintainer time, often requiring work stoppages and rework to remediate issues that are not actually issues. SCA tools often highlight their automated functionality which submits pull requests (PRs) to maintainers via GitHub to remediate issues. However, in the case of false positives, this just turns into unnecessary extra work for maintainers, who often tend to ignore such PRs. One prominent maintainer who we recently interviewed said:
“The number one thing [that would help me develop more securely] would be to reduce the number of false-positive security vulnerability reports. They are currently completely unusable. I cannot express in strong enough terms how bad security vulnerability reports in the node.js ecosystem are. They are a complete disaster.”
False positives can also create unnecessary work for security analysts, requiring them to gather data on the type of security risks, or for compliance specialists, who need to research license information to ascertain legal exposure.
Because it is so difficult to differentiate between signal and noise (real vs false issues), some application development and security leaders lack confidence in scan results—meaning important issues can actually end up slipping through the cracks.
Tidelift’s approach
Our mission at Tidelift is to make open source work better for everyone—the creators, maintainers, and users of open source. We partner directly with maintainers and pay them to ensure that their packages meet enterprise standards around security, maintenance, and licensing. As part of this work, when vulnerabilities are identified from NVD or any other database, we ask maintainers to clearly indicate whether or not their package contains a vulnerability, thus potentially exposing the vulnerability to package users.
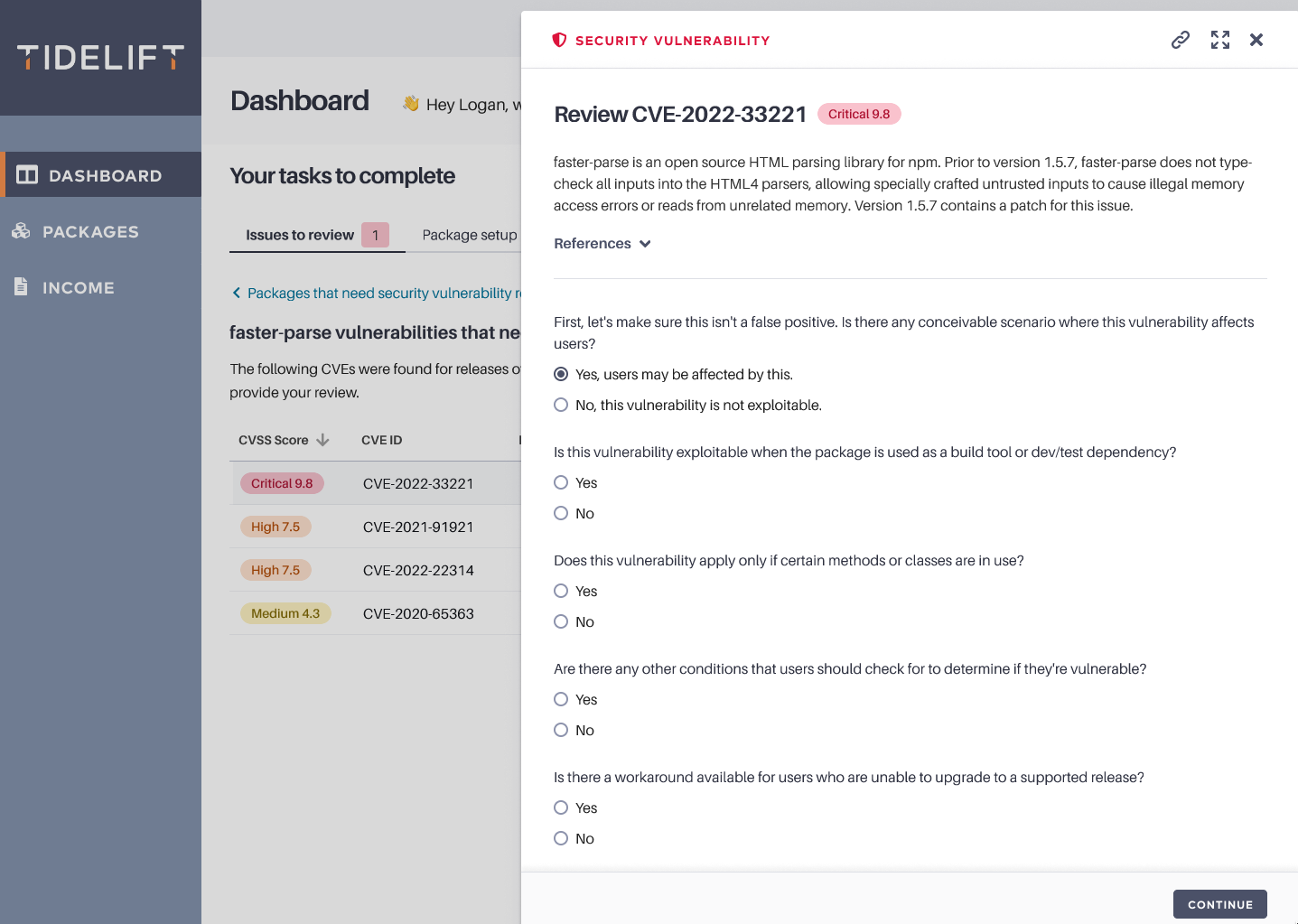
Figure 1: Maintainers use Tidelift to document whether a vulnerability is a false positive or not
In either case, maintainers also provide additional information that can help customers make informed decisions on how to move forward.
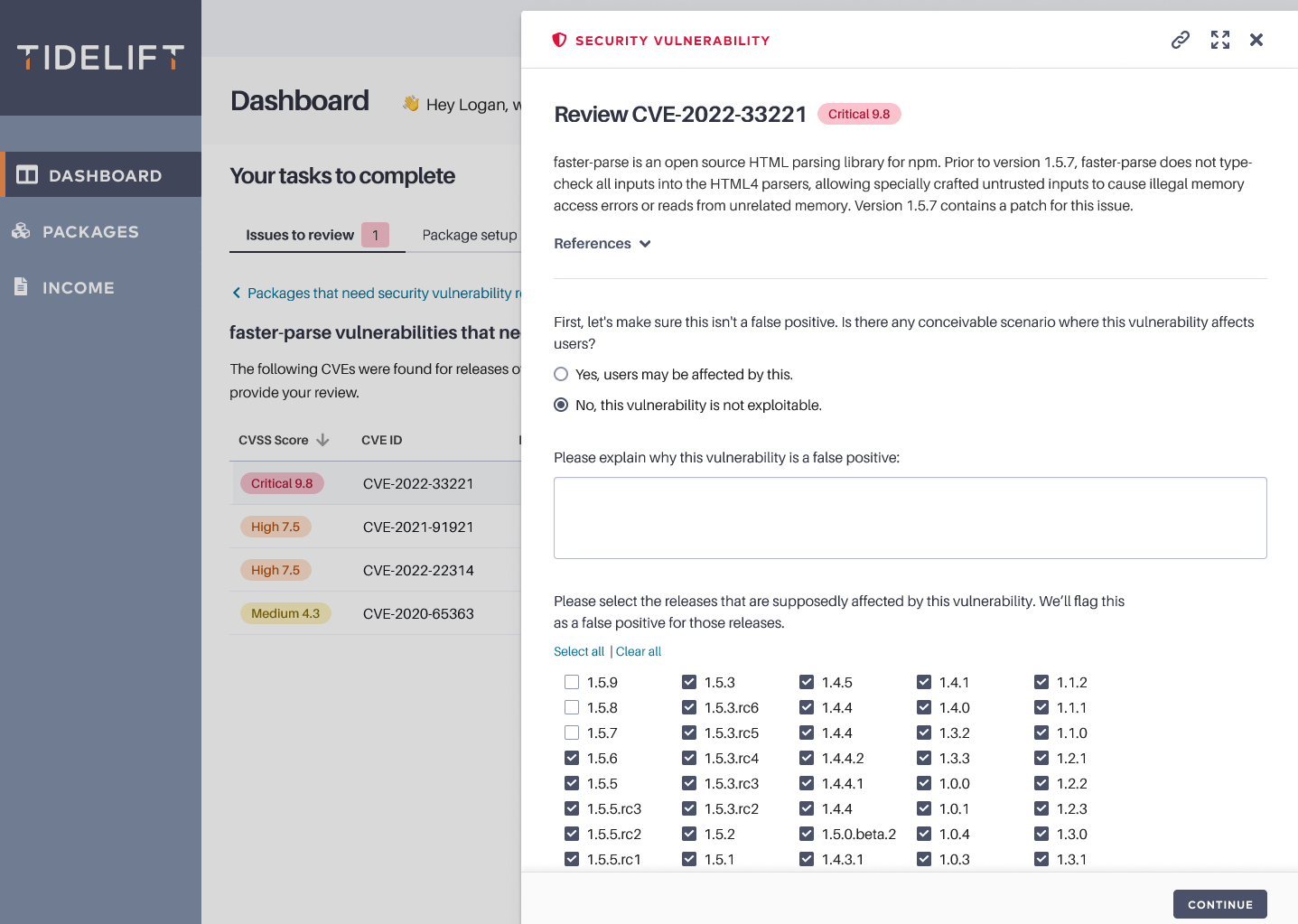
Figure 2: Maintainers use Tidelift to provide additional contextually relevant information so customers can make informed decisions
The Tidelift Subscription uses a software and people based approach to managing open source effectively for application development teams. With maintainer-validated data on security vulnerabilities, organizations using the Tidelift Subscription can spend less time wading through false positives and more time confidently moving forward with their open source decision making.
Find out more about how the Tidelift Subscription can help your organization manage open source effectively.

 50 Milk St, 16th Floor, Boston, MA 02109
50 Milk St, 16th Floor, Boston, MA 02109